
In any software project, testing relies heavily on having the right data. For large projects – characterized by complex business logic, intricate data relationships, multiple integrations, large teams, and stringent compliance requirements – managing test data effectively transforms from a simple necessity into a complex, critical discipline known as Test Data Management (TDM).
Inefficient TDM can lead to slowed testing cycles, unreliable results, environment contention, security risks, and ultimately, impact project timelines and software quality.
This article provides a comprehensive overview of the challenges and effective strategies for managing test data efficiently in large, complex software development environments.
The Challenges of Test Data in Large Projects
Why is TDM particularly difficult at scale? Several factors converge:
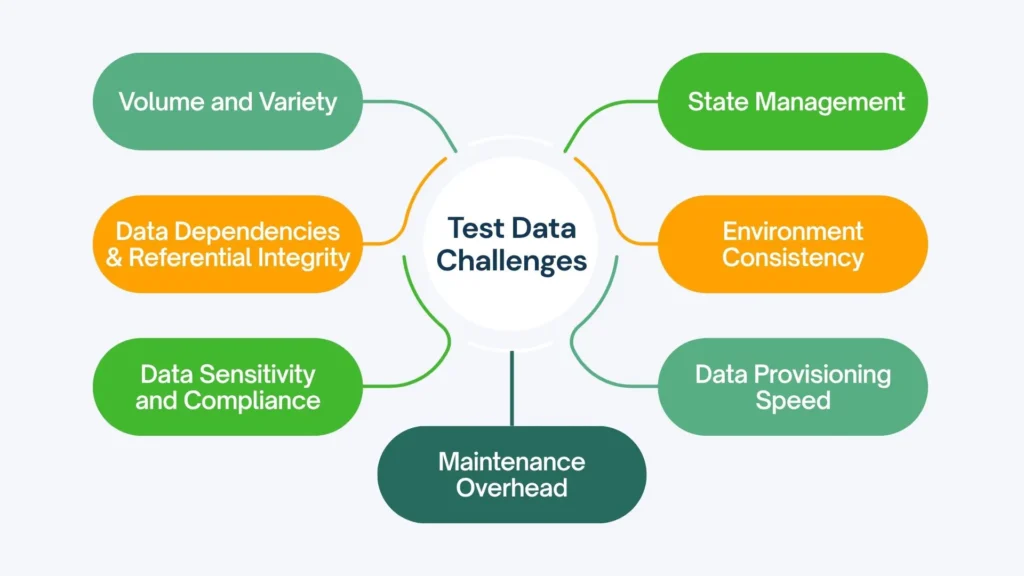
Volume and Variety
Large applications often require vast amounts of data covering numerous states, scenarios (happy path, edge cases, errors), user roles, historical conditions, and permutations to ensure adequate test coverage.
Data Dependencies and Referential Integrity
Data rarely exists in isolation. In complex relational databases or interconnected microservices, entities have dependencies (e.g., an order requires a customer, products, and addresses).
Creating or selecting test data must preserve these relationships; otherwise, tests will fail for reasons unrelated to the application logic.
Data Sensitivity and Compliance
Production datasets often contain Personally Identifiable Information (PII), financial data, health information, or other sensitive content subject to regulations like SOC 2, GDPR, CCPA, HIPAA, etc.
Using real production data in non-production environments is often prohibited or requires stringent anonymization (masking).
State Management
Tests often modify data (e.g., changing a user’s status, consuming a unique coupon code). Ensuring tests start with data in the correct, known state and managing data consumption across parallel test runs is crucial for reliable results. Data needs frequent refreshing or resetting.
Environment Consistency
Large projects typically have multiple non-production environments (Development, QA, Staging, Performance, UAT). Ensuring consistent, reliable, and appropriate test data is available across all these environments is a significant logistical challenge.
Data Provisioning Speed
Especially with Agile and DevOps practices emphasizing fast feedback loops, testers and automated test suites need the right data on demand. Slow, manual data setup processes create bottlenecks.
Maintenance Overhead
As the application evolves, the database schema changes, business rules are updated, and test data requirements shift. Keeping test data sets, generation scripts, and masking routines up-to-date requires ongoing effort.
Key Strategies for Effective Test Data Management
Addressing these challenges requires a multi-faceted strategy. Here are key technical approaches:
1. Synthetic Data Generation
Creating realistic-looking data from scratch avoids PII issues and allows precise control over generated scenarios.
- Techniques:
- Custom Scripting: Using SQL, Python, Java, or other languages to programmatically insert data. Offers maximum control but requires significant development and maintenance effort, especially for complex relationships.
- Data Generation Libraries: Leveraging libraries like Faker (available for most popular languages) significantly simplifies generating realistic fake names, addresses, dates, emails, text, numbers, etc. These are often used within custom scripts.
- Dedicated Data Generation Tools: Commercial or open-source tools often provide GUIs, understand database schemas, offer pre-defined data generators, help manage relationships, and can generate large volumes efficiently. Examples include tools from Redgate, Broadcom, Informatica, and services like Mockaroo.
- Considerations: While synthetic data avoids PII, making it statistically representative of production data distribution can be challenging. Maintaining complex data relationships requires careful design of the generation logic.
2. Production Data Extraction: Subsetting and Masking
Using a subset of production data can provide realistic complexity and volume, but requires rigorous anonymization.
- Data Subsetting: The process of extracting a smaller, targeted, yet referentially intact portion of a production database. This is technically complex because it must preserve all necessary relationships between tables/entities. Simple table sampling often breaks foreign key constraints. Specialized TDM tools are usually required to perform subsetting reliably while maintaining integrity.
- Data Masking (Anonymization): The process of replacing sensitive data elements with fictitious but realistic-looking data after extraction (subset or full copy in a secure environment). Essential for compliance. Common techniques include:
- Substitution: Replacing values with others from a predefined dictionary or generated via libraries (like Faker).
- Shuffling: Randomly reordering values within a column.
- Encryption / Tokenization: Encrypting sensitive data, potentially using Format-Preserving Encryption (FPE) so it fits the original data format.
- Nulling / Deletion: Removing sensitive values entirely.
- Number/Date Variance: Applying random offsets.
- Masking Out: Replacing characters (e.g., XXX-XX-XXXX).
- Considerations: Direct use of production data, even masked, carries inherent risks and requires strict security controls on the masking process and target environments. Subsetting requires sophisticated tooling. Masking algorithms must ensure the resulting data is still valid for application logic (e.g., masking an email must still result in a valid email format).
3. Data Refresh and State Management
Ensuring tests run against data in a known, consistent state is vital.
- Refresh Strategies:
- Database Restore: Restoring the test database from a clean “golden copy” backup. Simple but potentially very slow for large databases.
- Database Snapshots: Utilizing storage system or database-native snapshot features to quickly capture and revert the database state. Much faster than full restores, but depends on underlying infrastructure.
- Delete and Regenerate: Running scripts to delete transactional data and regenerate it using synthetic methods. Faster than restoring if generation is efficient.
- Application-Level APIs: Using dedicated API endpoints (if built into the application) to reset specific entities or scenarios. Often the most targeted and fastest method.
- State Management within Tests:
- Idempotent Tests: Designing tests (especially API tests) to produce the same result regardless of how many times they are run, often by creating and cleaning up their own required data within the test scope.
- Transactional Control: Using database transactions within tests to roll back any changes upon test completion. Effective for some integration tests but may not mimic real application behavior.
- Containerization: Using tools like Docker and Testcontainers to spin up ephemeral databases with pre-defined data for each test suite, ensuring complete isolation.
4. On-Demand Test Data Provisioning
Making the right data available quickly is key to efficient testing cycles.
- Self-Service Mechanisms: Providing web portals or CLIs where testers or automation frameworks can request specific data sets based on defined parameters (e.g., user type, region, account status).
- API-Driven Provisioning: Tests interact directly with a Test Data API to request and receive the necessary data (or identifiers for pre-existing data) just before execution. This makes tests more self-sufficient.
- Data Reservation: Implementing a system to allow tests to “lock” or reserve specific data records/sets while they are in use, preventing conflicts during parallel test execution.
- Data Pooling: Maintaining readily available pools of common data types (e.g., new users, users with specific permissions) that can be quickly allocated.
5. Test Data Storage and Governance
Proper storage and governance provide control and consistency.
- Centralized Repositories: Using dedicated database instances or schemas for storing master test data sets, golden copies, or generated data pools.
- Version Control for TDM Artifacts: Treating data generation scripts, configuration files, masking rules, and subsetting definitions as code – store them in a version control system like Git for history tracking, collaboration, and reproducibility.
- TDM Platforms: Utilizing integrated commercial TDM platforms can centralize many aspects like data discovery, profiling, masking, generation, subsetting, and provisioning.
- Governance: Establishing clear ownership, standards, processes, and security policies for test data creation, storage, masking, and usage.
→ Related content: Best Practices for Writing Effective Test Cases
Selecting the Right TDM Approach and Tools
There is no single “best” approach. The optimal strategy depends on factors like:
- Application Complexity and Data Relationships: Highly interconnected data often benefits from sophisticated subsetting or model-based generation.
- Data Sensitivity and Compliance Needs: Strict regulations heavily influence the need for robust masking or purely synthetic generation.
- Testing Types: Performance testing often requires large volumes (subsetting/generation), while exploratory testing might use targeted manual creation or synthetic data.
- Team Skills and Resources: Complex TDM tools require expertise and investment; simpler scripting might be feasible for smaller needs or skilled teams.
- Budget: Commercial TDM platforms can be expensive.
- Need for Speed: CI/CD pipelines demand fast, automated provisioning (APIs, containerization).
Often, a hybrid approach is most effective, combining synthetic generation for specific scenarios and edge cases with masked production subsets for realistic volume and complexity testing.
Where AgileTest Fits In
AgileTest is a comprehensive test management tool integrated with Jira, supporting agile teams through efficient test case and execution management.
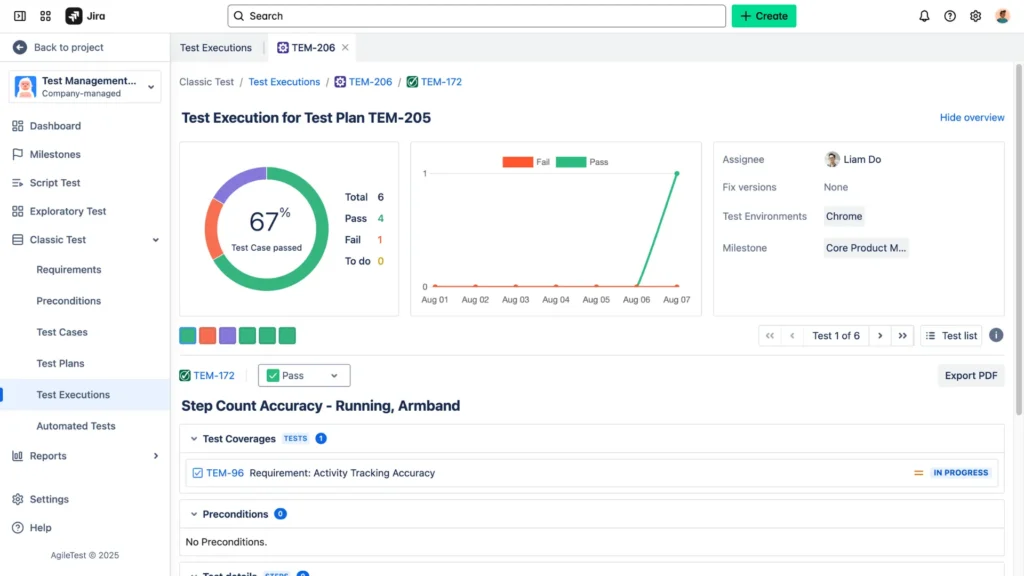
It enables exploratory and automated testing, integrates with CI/CD pipelines for automated workflows, and helps maintain compliance with robust reporting and traceability.
Used alongside specialized TDM tools, AgileTest enhances test data management and accelerates delivery.
Conclusion
Efficient Test Data Management is a cornerstone of effective quality engineering in large-scale projects. It requires moving beyond ad-hoc data creation towards a planned, strategic approach.
By understanding the inherent challenges and leveraging a combination of synthetic data generation, careful production data handling (subsetting and masking), robust refresh mechanisms, on-demand provisioning, and strong governance, development and testing teams can significantly improve the speed, reliability, and coverage of their testing efforts.
Investing in a solid TDM strategy is investing in faster feedback loops, reduced risks, and ultimately, higher quality software.


