Self-corrective RAG is quickly becoming one of the most important techniques in AI testing. While traditional RAG helps models pull information from external documents, it still struggles with issues.
This article breaks down what RAG is, its limitations, and how self-corrective RAG bridges the gaps.
1. What Is Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation, or RAG, is an AI architecture that enhances large language models (LLMs) by giving them access to external knowledge. RAG does not rely solely on what the model has learned during training. Instead, it can retrieve relevant information in real time and use that information to generate more accurate responses.
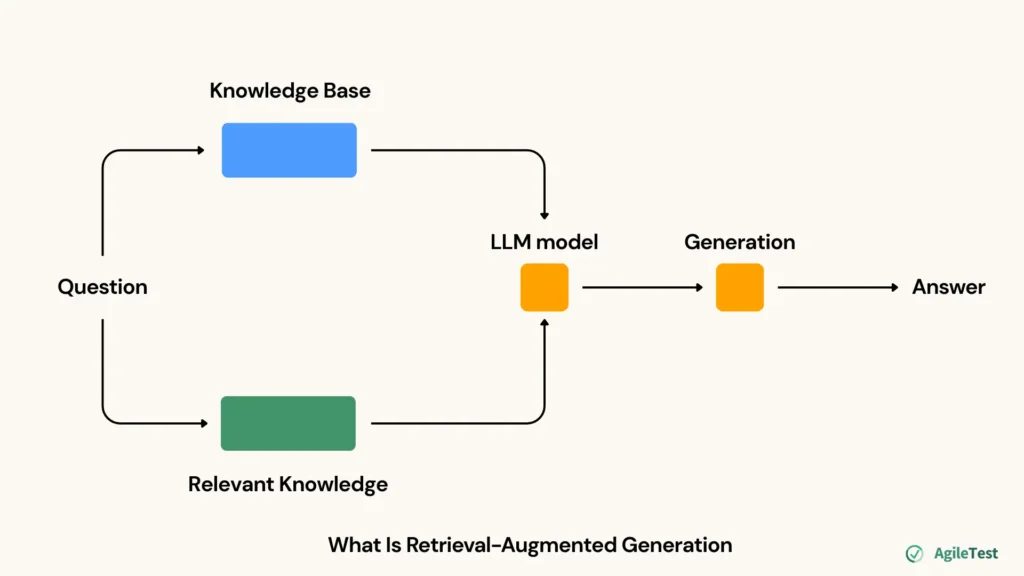
You can see lots of RAG applications in daily life. For example, QA teams using tools like AgileTest can use an AI assistant that searches through internal test documentation during testing. In a traditional setup, if a tester encounters an issue that isn’t documented in the test plan or user guide, the chatbot would simply be unable to answer. But with a RAG-powered assistant, the system can dig deeper. It can look into past defect reports, previous notes, and similar issues to provide a relevant, context-aware answer.
2. RAG Is Not Perfect
However, the RAG system is not perfect. There are some limitations that can impact the AI output. These challenges usually fall into three main areas:
Retrieval Problems
RAG relies heavily on finding the right information. If the system retrieves the irrelevant or inaccurate documents, the final answer will be misleading. When retrieval is weak, the AI has nothing solid to base its response on. Even a powerful model can produce an answer that sounds confident but isn’t actually correct.
For example, when you ask a RAG model for app instructions, it can accidentally look for an outdated guide. Because the UI and steps have changed, it would be hard for you to follow.
Generation Problems
In case the model can retrieve information, it may struggle to give a good answer. Sometimes, the information in the documents is not an exact match, and AI can misinterpret or hallucinate the answer. As a result, you can receive a logic output, but it is not correct.
For instance, the RAG system might pull instructions from a guide that explains how to perform software environment testing. However, the document doesn’t mention that you must set up specific hardware or software first. The AI then generates the answers with assumptions, leaving you with guidance that looks right but won’t work in practice.
Evaluation Problems
One more issue that can take place is that traditional RAG systems don’t check their own work. Once the model retrieves some information, it simply generates a response without checking whether the answer is complete or relevant.
For illustration, you may ask the AI about running regression tests. The model retrieves some instructions and generates a clean answer, but it doesn’t check whether the steps are complete. It might leave out essential actions, like refreshing data or resetting the environment, since those details were in separate documents.
3. Self-corrective RAG
Given these challenges, it’s clear that traditional RAG still leaves significant gaps. These limitations are exactly why self-corrective RAG comes in. In other words, self-corrective RAG aims to close the gap between “sounds correct” and “is correct,” making AI responses more reliable, more complete, and better aligned with what users actually need.
Level of Confidence
Self-corrective RAG is the RAG, but with an additional verification loop that evaluates the retrieved information and refines it before finalizing the answers. To do this, the evaluator categorizes the document into 3 levels of confidence:
Correct:
The information is considered correct when the retrieved information clearly answers the question and matches the user’s intent. The model can safely use it to generate the final response.
Incorrect:
The information is marked incorrect when it does not relate to the question or contradicts what is needed. In this case, the system may discard it and attempt to retrieve better context.
Ambiguous:
The information is labeled as ambiguous when it is partially relevant but incomplete, unclear or not given. This signals the model to re-check, gather additional context, or refine its reasoning before producing the final output.
How Self-Corrective RAG Works
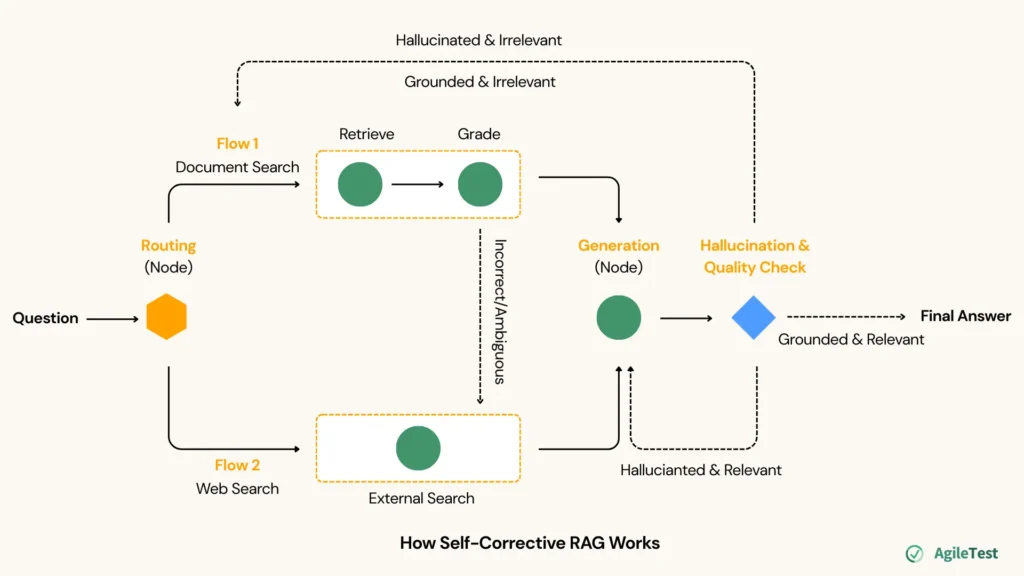
- Question: Everything begins with a user question. The system receives a query and prepares to determine where the best answer should come from.
- Routing (Node): The system first decides whether the question is related to the internal knowledge base or needs to search from external sources.
- Searching Flows:
- Flow 1: Document Search: AI follows this flow if the question matches content inside the indexed documents. These documents can come from your guidelines, notes, historical instructions, etc. AI will retrieve information from these documents, then categorize the quality into the 3 previously mentioned levels of confidence. If the information is incorrect or ambiguous, AI will redirect the flow to search from external sources.
- Flow 2: Web Search: AI follows this flow if the question falls outside the indexed scope. It will look for the answer from external knowledge, such as the company website, search engine, etc.
- Generation (Node): Either the AI follows the Document Search or Web Search flows, and they all come to the Generation stage. At this node, AI will draft the answer based on the data collected.
- Hallucination & Quality Check (Node): The final stage is where the “self-corrective” part happens. The system evaluates the generated answer along two dimensions: Hallucinated (contains made-up up detailed) and Relevant (addresses the questions). If the answers are:
- Hallucinated & Irrelevant: redirect to the Searching Flows (2) to retrieve information and draft the answer again.
- Hallucinated but Relevant: redirect to the Generation node (5) to consolidate the answer.
- Grounded but Irrelevant: redirect to the Searching Flows (2) to retrieve information from more accurate sources of data.
- Grounded & Relevant: finalize the answers and provide them to users.
4. Self-Corrective RAG Application With Multistep Agents
You can apply Multi-step Agents to enhance the quality of AI from Self-corrective RAG models. Here is a prompting example to grade document quality and check hallucination & quality.
Iterative Retrieval and Grading
Instead of accepting the first set of retrieved documents, the multi-step RAG agent evaluates each piece of context before using it. The agent assigns confidence levels (Correct, Incorrect, Ambiguous) and decides whether additional retrieval is needed.
A simplified example of a grading prompt:
prompt_template = """
You are an AI document evaluator. Your task is to judge whether each retrieved document helps answer the question.
Classify each document into one of the following:
1. **Correct**:
- The document directly answers the question.
- It matches the version, environment, and context.
- No contradictions with other documents.
2. **Incorrect**:
- The content conflicts with the question.
- Wrong version, outdated instructions, or unrelated topic.
3. **Ambiguous**:
- Partially relevant but incomplete.
- Missing prerequisites, unclear wording, or context-specific details.
### Your Tasks:
1. Assign a label (Correct / Incorrect / Ambiguous) to each document.
2. Explain the reasoning behind your classification.
3. Suggest whether new retrieval should be triggered.
Return results as structured JSON.
"""
Hallucination & Quality Review
A sample prompt for reviewing the answer can look like:
review_prompt = """
You are an AI answer evaluator. Your task is to check whether the generated answer is grounded in the retrieved documents.
Check for:
1. **Hallucination**:
- Any statement not supported by the documents.
2. **Relevance**:
- Does the answer actually solve the user's question?
3. **Completeness**:
- Are any critical steps or prerequisites missing?
4. **Contradictions**:
- Does the answer conflict with the retrieved context?
### Output:
- Identify issues (if any).
- Suggest improvements.
- Indicate whether to regenerate the answer.
- Final decision: True (acceptable) or False (needs revision).
"""
This acts like a “human reviewer” ensuring the answer is grounded, accurate, and logically complete.
Final thoughts
Self-corrective RAG is a major step forward in making AI more dependable. Adding verification, refinement, and evaluation loops on top of traditional RAG pipelines helps reduce hallucinations and ensures answers are grounded, complete, and aligned with user intent. As AI continues to play a larger role, self-corrective RAG will become essential for building systems users can trust.
AgileTest is a Jira Test Management tool that utilizes AI to help you generate test cases effectively. Try it now